サーバーサイドトラッキングとクライアントサイドトラッキング:知っておくべきこと
現在、消費者はオンラインプライバシー権についてより意識を高めており、その結果、広告ブロッカーの広範な使用やより厳しいクッキーポリシーが導入されています。このトレンドにより、組織は以下のような重要な課題に直面しています。
- 限定的なデータ収集:ユーザーの行動を理解し、顧客に響くパーソナライズされた広告を届けるのが難しくなっています。
- 新しい規制への適応に伴うコンプライアンスコストの上昇:リソースと予算が圧迫されています。
- データプラクティスに対する顧客の懐疑心の高まり:ブランドの評判に影響を与えています。
- データプラクティスに関する明確なコミュニケーションを通じて、顧客との信頼を維持し、透明性を高めることが必要です。
サーバーサイドトラッキングは、これらの問題を解決するのに役立ちます。この記事では、サーバーサイドトラッキングの仕組み、実装方法、利点について説明します。
サーバーサイドトラッキングとは何ですか?
サーバーサイドトラッキングとは、ユーザーデータがサーバーによって直接収集される手法を指します。
サーバーサイドトラッキングの主な利点は、データの収集、処理、保存がウェブサイトのサーバー上で直接行われることです。
例えば、訪問者がウェブサイトとインタラクションした場合、サーバーはバックエンドシステムを通してそのアクティビティをキャプチャし、より高度なデータコントロールとセキュリティを可能にします。
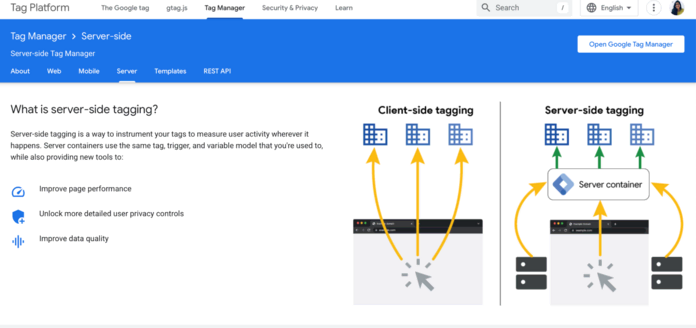
クライアントサイドトラッキング vs. サーバーサイドトラッキング
ユーザーデータを収集する方法には、クライアントサイドとサーバーサイドの2つがあります。
それぞれの違いを理解しよう。
クライアントサイドトラッキング 注意点を伴う利便性
クライアントサイドトラッキングは、JavaScriptタグ、ピクセル、その他のスクリプトをウェブサイトのコードに直接埋め込みます。ユーザーがサイトにアクセスすると、これらのタグが起動し、ブラウザからデータを収集します。この情報には、ページビュー、ボタンのクリック、フォームの送信、その他のユーザーアクションが含まれます。
収集されたデータは、GoogleアナリティクスやAdobeアナリティクスのようなサードパーティの解析プラットフォームに直接送信されます。
この方法は比較的簡単に導入できます。というのも、マーケティング担当者は多くの場合、開発者の大規模なサポートを必要とせずにこれらのタグを導入できるため、迅速な調整やA/Bテストが可能になるからです。
しかし、課題もあります。
広告ブロッカーやITP(Intelligent Tracking Prevention)などのブラウザのプライバシー設定は、サードパーティタグがデータを収集する能力を制限します。
その結果、データのギャップや不正確さが解析レポートを歪め、誤ったビジネス上の意思決定につながる可能性があります。
また、多数のJavaScriptタグに依存すると、Webサイトのパフォーマンスに悪影響を及ぼし、ページの読み込み時間が遅くなったり、ユーザーエクスペリエンスに影響を与えたりする可能性があります。これは、処理能力やネットワーク速度が制限されがちなモバイルデバイスでは特に当てはまります。
では、サーバーサイド・トラッキングがどのように変わるのか見てみましょう。
サーバーサイド・トラッキング コントロールと信頼性
サーバーサイド・トラッキングは、データ収集の負担をユーザーのブラウザから企業がコントロールするサーバーにシフトします。
ユーザーのデバイスから直接発射されるJavaScriptタグに依存する代わりに、ユーザー・インタラクションはまずビジネス自身のサーバーに送信されます。ここで、データを処理し、強化し、解析することができます。
この方法は、データの完全性のコントロールの強化、プライバシーの改善など、多くの利点を提供します。
サーバーサイドトラッキングの利点
サーバーサイドトラッキングは、従来のクライアントサイドの方法に代わる説得力のある方法を提供し、数多くのビジネス上の利点をもたらします。それらについて見ていきましょう。
データ精度の向上
この方法は、ブラウザの制限をバイパスすることで、広告ブロッカーやクッキー制限による不正確さを軽減します。その結果、収集されたデータはより信頼性が高くなり、より優れた解析とマーケティングアトリビューションにつながります。
データ最小化
データ最小化はデータ保護の基本原則です。これは、組織が特定の目的のために厳密に必要なデータのみを収集することを強調するものです。
サーバーサイドのトラッキングでは、データを解析プラットフォームに送信する前に、必要なデータポイントだけを収集し、余分なものは破棄することになります。これにより、組織は過剰な個人情報の蓄積を避け、データ漏洩や悪用のリスクを減らすことができます。
例えば、ユーザーがeコマースサイトで商品を購入した場合を考えてみましょう。
クライアントサイドのトラッキングスクリプトでは、ユーザーのIPアドレス、ブラウザの種類、オペレーティングシステム、さらには訪問した他のウェブサイトの詳細など、さまざまなデータを不注意に収集してしまう可能性があります。
しかし、コンバージョンの場合、組織が知る必要があるのは、購入金額、商品ID、ユーザーIDS、タイムスタンプだけです。
サーバーサイドのトラッキングは、不必要な情報をフィルタリングします。これにより、プライバシーへの影響を軽減し、データ解析と保存を簡素化します。
クロスデバイス・トラッキング機能
サーバーサイド・トラッキングは、使用するデバイスに関係なく、顧客の行動を統一的に把握することができるため、よりパーソナライズされ、ターゲットを絞ったマーケティング・キャンペーンが可能になります。
詳細なイベントトラッキング
サーバーサイド・トラッキングは、決済確認など、ウェブサイト外で発生するイベントのトラッキングを支援します。企業は、最初のインタラクションから最終的な購入まで、カスタマージャーニー全体に関する洞察力を得ることができ、あらゆるタッチポイントを最適化することができます。
プライバシー・コンプライアンスの強化
GDPRやCCPAのような規制が強化される中、企業はサーバーサイド・ソリューションを通じて、ユーザーの同意とデータ取り扱い慣行をより適切に管理することができます。
サーバーサイドのセットアップにより、ユーザー同意の尊重が容易になります。ユーザーがオプトアウトした場合、サーバーサイドのロジックは、一元的にすべての発信解析コールからユーザーのデータを除外することができます。
サーバーサイドの方法は、データが最小限のリスクで収集され、保護されていることをユーザーと規制当局に安心させます。
政府や銀行のような分野では、このレベルの管理は、しばしば注意義務の譲れない部分です。
クッキーの有効期限の延長
最新のブラウザがユーザーのプライバシーを優先するにつれ、従来のウェブサイト追跡はますます障害に直面しています。SafariのITPのようなイニシアチブはサードパーティのクッキーをブロックし、ファーストパーティのクッキーの使用も制限します。
FirefoxやBraveなどの他のブラウザも同様の方法を導入しており、Chromeはサードパーティのクッキーを段階的に排除し始めています。これらのクッキーに依存するリターゲティングとクロスサイト解析には、大きな課題があります。
サーバーサイド・トラッキングは、企業がより長い期間にわたってデータを収集できるようにすることで、これを克服します。
ウェブサイトのサーバーが直接クッキーを設定する場合、そのクッキーはブラウザ内で実行されるJavaScriptコードによって作成されるクッキーよりも長持ちすることがよくあります。これによってウェブサイトは、ブラウザがトラッキングに課す制限のいくつかを回避することができ、訪問者が後でサイトに戻ったときにその訪問者を記憶することができるため、より良い顧客インサイトを得ることができます。さらに、サーバーサイド・トラッキングは通常、クッキーをファーストパーティ・データとして分類するため、ブラウザや広告ブロッカーによるブロックの影響を受けにくくなります。
サーバーサイドのトラッキング 責任と考慮点
サーバーサイドトラッキングは強力な機能を提供しますが、同時に責任も増大することを忘れないでください。企業は、プライバシー規制とユーザー同意の遵守に警戒し続けなければなりません。例えば、誰かがオプトアウトした場合はデータを送信しないなど、サーバーがユーザーの同意に従うようにするのは企業次第です。
サーバーサイドのセットアップには技術的な複雑さが伴うため、特定や解決がより困難なデータエラーにつながる可能性があります。そのため、データの整合性を保つためには、モニタリング・プロセスと品質保証の実践が不可欠です。
サーバーサイドトラッキングの仕組み
ユーザーがウェブサイトとインタラクトする(例えば、ボタンをクリックする)と、このアクションがイベントをトリガーします。イベントはページビューからフォームの送信まで何でも可能です。
バックエンドシステムは、イベントの種類、ユーザーID、タイムスタンプなどの関連する詳細を取得します。この情報は、ユーザーの行動を理解し、意味のある解析を作成するのに役立ちます。
取得されたデータは、組織のサーバー上で直接処理されるため、すぐに検証を行うことができます。例えば、組織はコンテキストを追加したり、無関係な情報をフィルタリングすることができます。
サードパーティのエンドポイントにデータを送信する代わりに、組織はすべてを独自のデータベースまたはデータウェアハウスに保存します。これにより、データのプライバシーとセキュリティを完全に管理することができます。
組織はSQLやPythonのようなツールを使って独自の解析を行うことができます。データを視覚化するために、カスタムダッシュボードやカスタムレポートをセルフホスト型の解析ツールを使って作成することができます。こうすることで、企業は複雑なデータを明確で実用的な方法で提示することができます。
サーバーサイド・トラッキングの導入方法
サーバーサイド・トラッキングは、4つの一般的な方法があり、それぞれコントロール、柔軟性、複雑さが異なります。
1. サーバーサイドタグマネジメント
この方法では、組織はGoogleタグマネージャーサーバーサイドのようなプラットフォームを使用して、サーバー上でトラッキングタグを管理します。
この方法は、コントロールと使いやすさのバランスを提供します。アプリケーションのコードを変更することなくタグのデプロイと管理ができるので、トラッキングの設定を素早く調整したいマーケティング担当者には特に便利です。
2. APIを介したサーバー間の直接トラッキング
この方法では、ユーザーのブラウザやデバイスに影響を与えることなく、2つのサーバー間で情報を共有します。
ユーザーが広告やウェブページにアクセスすると、一意の識別子が生成され、サーバーに保存されます。
ユーザーが購入などのアクションを起こした場合、一意の識別子は広告主のサーバーからAPI経由でプラットフォームのサーバー(グーグルやフェイスブック)に直接送信されます。
開発の手間はかかりますが、きめ細かなデータ管理が必要な組織には理想的です。
3. サーバーSDKを組み込んだ解析プラットフォームを使用する
もう一つの方法は、サーバーサイドのコードをインストルメントするために、様々なプログラミング言語用のSDKを提供するMatomoのような解析プラットフォームを採用することです。
これは、プラットフォームのアナリティクス機能との統合を容易にし、主に単一のアナリティクス・プラットフォームを使用し、そのサーバーサイド機能を使用したい組織に適した選択です。
4. ハイブリッドアプローチ
最後に、組織はクライアントサイドとサーバーサイドのトラッキングを組み合わせることで、異なるデータタイプを取得し、精度を最大化することもできます。
この方法では、特定のインタラクション(UIイベントなど)にはクライアントサイドのスクリプトを使用し、より機密性の高いデータや重要なデータ(トランザクションなど)にはサーバーサイドのトラッキングを使用します。
これらは一般的なアプローチだが、専用の解析プラットフォームも役に立ちます。例えばMatomoは、2つの特定の方法によってサーバーサイドのトラッキングを容易にします。
サーバーログの使用
Matomoは、各リクエストをキャプチャするApacheやNginxなどの既存のウェブサーバーログをインポートすることができます。すべてのページビューやリソースロードがデータポイントになります。
Matomo のログ処理スクリプトはログファイルを読み込み、何百万ものヒットをインポートします。これにより、サイトにコードを追加する必要がなくなり、クライアントサイドのスクリプトを使用しない基本的なページ解析(URLなど)、特にセキュリティに敏感なサイトに適しています。
Matomo トラッキング API の使用 (サーバサイド SDK)
このメソッドは、アプリケーションコードと Matomo の API 呼び出しを統合します。例えば、ユーザが特定のアクションを実行すると、サーバはトラッキングエンドポイントである Matomo.php にリクエストを送信し、ユーザ ID やアクションなどの詳細が含まれます。
Matomoは、これらの呼び出しを簡素化するために、PHP、Java C#、およびコミュニティSDKのSDKを提供しています。これらは、ページビューだけでなく、バックエンドからのダウンロードやトランザクションのようなカスタムイベントのトラッキングを可能にし、GoogleのMeasurement Protocolと同様に機能しますが、Matomoインスタンスにデータを送信します。
データプライバシー、規制、Matomo
プライバシーへの関心が高まり、GDPR や CCPA のような規制が厳しくなるにつれ、企業はユーザーの同意とデータ保護権を尊重したデータ収集方法を採用しなければなりません。
サーバーサイドトラッキングは、企業がファーストパーティデータをサーバーから直接収集することを可能にし、一般的にプライバシー規制により準拠していると考えられています。
Matomoは、オープンソースのウェブ解析プラットフォームとして人気があり、プライバシー保護に取り組んでいる。組織には100%のデータ所有権とコントロールが与えられ、デフォルトではデータが第三者に送信されることはありません。
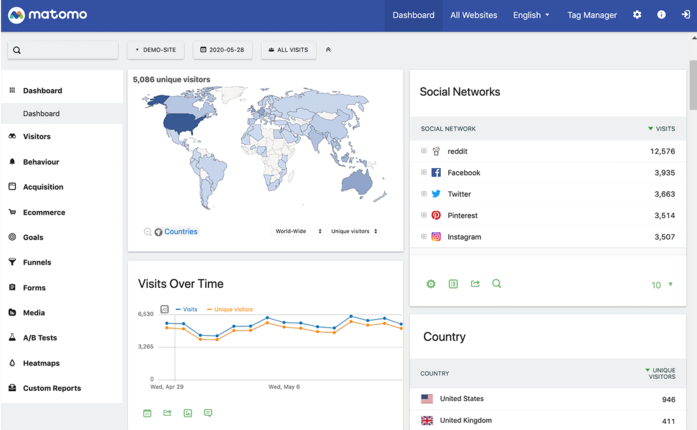
Matomoは、Google Analyticsに匹敵するダッシュボードとセグメンテーションを備えたフル機能の解析プラットフォームです。セルフホストが可能で、DoNotTrack設定とIPアドレスの匿名化機能を提供します。
EU 委員会やスイス政府など、データ主権を必要とする政府や組織は、その強力なコンプライアンス態勢により、ウェブ解析に Matomo を選択しています。
データ収集とユーザープライバシーのバランス
広告ブロッカーやその他の制限は、データの正確性を妨げます。サーバーサイドトラッキングは、ユーザーのプライバシーを尊重しながら、サーバー上のデータを取得し、より信頼性の高いものにします。Matomoはサーバーサイドトラッキングをサポートしており、100万以上のウェブサイトがデータ戦略を最適化するためにMatomoを使用しています。