Googleアナリティクスのサンプリング:なぜ重要なのか、どうすれば回避できるのか
マーケティング上の意思決定がウェブサイト解析に依存する場合、正確さが重要になります。しかし、Googleアナリティクスをはじめとする解析プラットフォームは、データをサンプリングしてレポートを作成します。
レポートが作成されるため、真のデータトレンドが誤って表示されることがあります。
この記事では、Googleアナリティクス4がどのようにデータサンプリングを使用しているのか、そのクォータ制限の変更、そしてなぜサンプリングされたデータが大量のウェブプロパティにとって依然として問題となり得るのかを探ります。
データサンプリングとは?
データサンプリングは、より大きなデータセット内の傾向を解析し特定するために、より小さなデータのサブセットを使用する統計解析手法です。
政治調査のように完全なデータセットを収集することが困難な場合や、データセットが大きすぎてすべてのデータを準備し計算することが困難な場合に役立ちます。
このどちらかが問題となる多くの業界では、標準的な手法です。例えば、ギャラップ社はアメリカ全人口を調査することはできませんので、代わりに代表サンプルを使っています。
サンプルが代表的であることを確認するには、サンプルを構成する被験者を注意深く選択します。このステップは、データの選択バイアスを避けるための鍵となります(詳細は後述)。
なぜGoogleアナリティクスはデータサンプリングを使用するのですか?
Googleアナリティクスは、特に無料ユーザーに対して、レポート用に処理するデータ量を制限しています。簡単に言えば、クラウドコンピューティングのリソースを節約するためです(AIを採用するリソースが増えるにつれて、コストが増加する可能性があります)。

データセットが大きければ大きいほど、レポートの計算を完了するために必要なコンピューティングリソースは多くなります。その結果、Googleアナリティクスは、短期的でデータ量の少ないレポートには完全なデータを使用し、より詳細な解析にはサンプルを使用する傾向があります。
例えば、トラフィックが限られているサイトの基本レポートを見てみましょう。チェックマークは、このカードが「サンプルなし」で、利用可能なデータを100%使用していることを示しています。(緑色のレポートアイコンに注目してください。)

しかし、トラフィックの多いウェブプロパティや、ファネル解析やコホート解析のような複雑なレポートでは、結果はほぼ確実にサンプリングされます。複数のデータセット、例えば2つのユーザーセグメント同士やベースラインと比較する場合、事態はさらに悪化します。GAの12ヶ月ファネルレポートは、下記のように利用可能なデータの48.3%しか使用していないかもしれません。

解析が高度になればなるほど、GAやその他の解析ツールは、全体像を示さない結果を出している可能性が高くなります。
Googleアナリティクス4におけるデータサンプリングの変更点
日没前のユニバーサルアナリティクスでは、サンプリングされていないレポートの最大サンプルサイズは50万ユーザーセッションでした。ウェブサイトが月に数千以上のユーザーセッションを受信する場合、これはすぐに問題になる可能性があります。
GA4への変更により、サンプリングのしきい値は1,000万 「イベント 」に設定されました。これは最初、大規模なアップグレードのように聞こえます。しかし、イベントは基本的に個々のデータ行であるため、レポートによっては、各セッションが数十の個別のイベントを表す可能性があることを考慮することが重要です。
つまり、トラフィック量だけが制限要因ではないのです。二次ディメンジョンを追加すればするほど、イベントのセットは(指数関数的に)大きくなります。このことは、当初はサンプリングされていないデータを使用していたレポートが、セグメントを比較したり、ニュアンスを追加するために再実行すると、サンプリングされたデータを使用するようになることを意味します。
Googleは、1000万件は 「標準レポート 」にのみ適用されるとしています。つまり、イベント数がはるかに少なくても、複雑なレポートはすぐにサンプルデータに依存し始めることになります。それ以上に、サンプリング方法やGAがどのようにランダムなサンプルを選ぶかについての公開情報は限られています。
結論は?データサンプリングは依然として、トラフィックの多いプロパティや高度なレポートを使用するマーケティング担当者に影響を与えます。カスタムディメンションやカスタムイベントの使用は、もう一つの制限要因です。
さらに詳しく: Googleアナリティクスの10の重要な制限事項
データサンプリングがウェブ解析で問題になる理由
Googleアナリティクスの公式説明では、データサンプリングを使用する理由について、1エーカーのデータを外挿することで、広大な敷地にある木の本数を推定することを例に挙げています。1エーカーあたり800本の木があり、100エーカーあるとすると、敷地内の木の推定総数は約80,000本となります。
フォレスターは、自分の区画の将来について賢いマーケティング上の決定を下すために、完全なデータ精度を必要としないので、これはかなり不誠実です。さらに、まずその地域の航空調査を行い、全長にわたって同等であることを確認するのは簡単です。これにより、森林の残りの部分を正確に表す1エーカーの木を選ぶことができます。
ウェブ解析では、サンプルの選択バイアスを避け、すべてのデータソースとサイト訪問者のタイプを均等に代表することは難しいです。
結局のところ、これは平均的なユーザーの行動を真に表すデータサンプルを見つけることが困難であることを意味します。アナリティクス・プラットフォームがたまたま特定のプロモーションからの訪問を多く選択した場合、販売数が膨れ上がったり、萎んだりする可能性があります。
また、これはデータの精度に影響を与える要因の一つに過ぎません。
一般的な誤差
さて、データはサンプリングされたものですが、どの程度悪いのでしょうか?平均して、レポートはかなり正確ですが、サンプルが少なければ少ないほど、典型的な誤差は大きくなります。
誤差は1%程度になることもありますが、複数のユーザーが、誤差が小さい範囲では30%程度 になる可能性があるとしています。
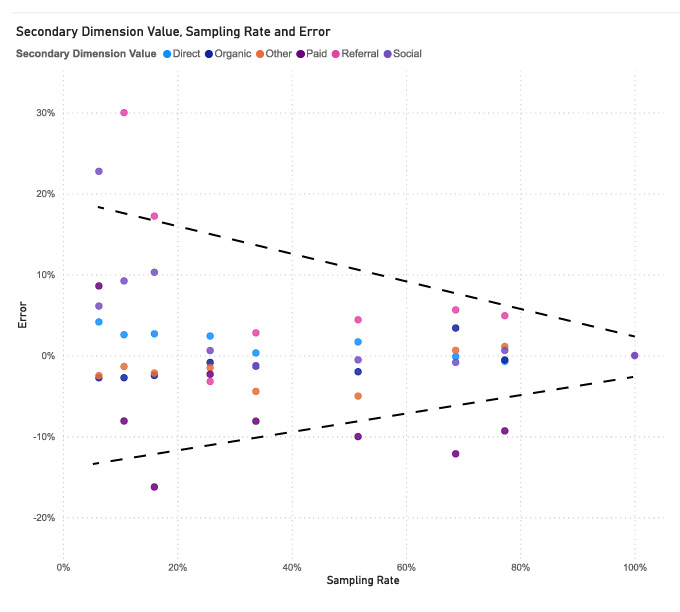
このため、1,000万イベントが年間トラフィックのごく一部に過ぎないような、大量のウェブサイトに対して正確なレポートを作成することは困難です。
単純な年間レポートのGAサンプリング率が50%を下回るのを見た後では、これは素晴らしいニュースとは言えません。また、これは長期的なセグメント比較(より多くの変数とイベントがミックスに追加されます)を行うことを考える前の話です。
Googleアナリティクスの精度が低い理由 はそれだけではありません。
Googleアナリティクスのデータサンプリングを減らす3つの方法
より正確なレポートをお望みですか?アクセス数の多いサイトのGoogleアナリティクスレポートのデータサンプリングを減らすには、以下の3つのアプローチのいずれかを使用します:
レポートの時間枠を減らして精度を上げる
ほとんどのユーザーは、より短い期間に焦点を当てることでサンプリングを避けることができます。日付範囲を縮小することで、イベントの総数がデータサンプリング制限を下回る可能性が高くなり、実際のデータで作業できるようになります。
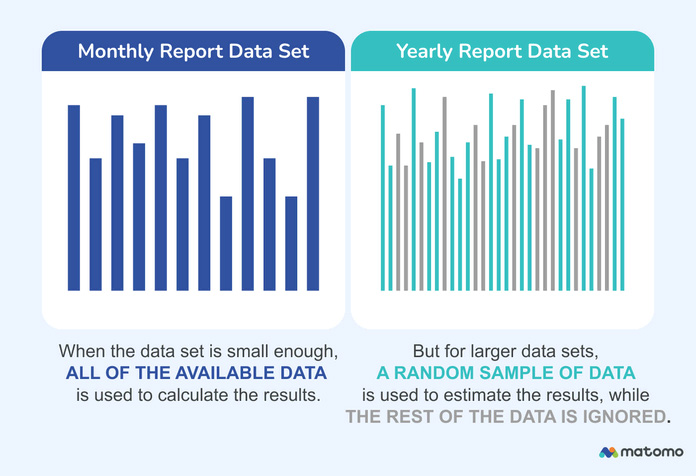
これは、新しいキャンペーンの影響など、短期的なトレンドを正確に見積もるには良いアイデアです。しかし、恒久的な解決策ではありません。
信頼性の高い長期レポートを作成するためには、非常に手間がかかります。例えば、データの精度が100%達成可能なのが30日分のレポートだけだとすると、1つの四半期レポートには3つのレポートのデータが必要になります。年次報告書はさらに負担が大きくなります。
さらに、セグメントベースのレポートは、すぐにサンプルデータに頼るようになるため、手作業で行う必要があります。
サンプルなしレポートのポイントは、シンプルで日付範囲を短くすることです。(徹底的な解析とは正反対に聞こえるかもしれませんが、その通りです。詳細な洞察力を得るには、小さなデータセットよりも大きなデータセットの方が望ましいです)。
サードパーティのデータ解析ツールにデータをエクスポートします(それでも制限のリスクはあります)
生データをサードパーティのデータ解析プラットフォームにエクスポートすることで、レポート作成時にサンプリングを使用するかどうかを完全に制御できる可能性があります。
例えば、Google Data StudioとGoogle BigQueryはデフォルトでサンプリングを使用しません。(スプレッドシート愛好家の中にはGoogleシートを使用している人さえいます)。
しかし、データのエクスポートはGA側でも制限されているため、残念ながら確実な解決策とはなりません。1日に100万件以上のイベントがある場合、エクスポートはサンプルに基づいて行われます。
プラットフォームによっては、短期間のリクエストから徐々にデータを収集する回避策があるかもしれません。ただし、動作が保証されているわけではないので、おそらく最良の解決策ではないでしょう。
Googleアナリティクス360にアップグレードします(そして「より詳細な結果」を選択する)
GAの有料版であるGoogleアナリティクス360にアップグレードすると、データクォータの上限がデフォルトで1億イベントに増加します。
「より詳細な結果」オプションを選択(エクスプローラビューのレポートまたは右上隅のカードのシールドアイコンをクリック)すると、上限が10億イベントに増加します。無料アカウントの場合、このシールドアイコンには赤いエクスクラメーションマークが表示されます。
それでも、このアップグレードは、データサンプリング以上の問題を解決することなく、GAにお金を払う必要があります。
さらに: GA360 vs GA4:主な違いと課題
信頼できる代替ツールに切り替えることで、データサンプリングを完全に回避します。
多くのGoogle Analytics代替ツール は、そもそもデータサンプリングを使用しないことでこの問題を完全に回避しています。要するに、総トラフィック量やレポートの複雑さにもよりますが、20〜50%多くのデータを開放することができるのです。
また、信頼性が高く正確な代替手段に切り替えるメリットはこれだけではありません。
GA4発売後もプライバシーに関する懸念があります
ますます厳しくなるプライバシー規制に対応してGoogleアナリティクス4がリリースされたとはいえ、規制当局はまだ満足しているとは言い難いです。特に、GA4はGDPRに関して複数の問題を抱えており 、デフォルトではまだ準拠していません。
また、罰金を科されることだけが問題ではありません。違反の報告によって準備不足が発覚した場合、解析ツールの変更やGA4のセットアップの完全な変更を命じられる可能性があります。チームがGA4への移行に数カ月を費やしていた場合、特に重要なキャンペーン中にこのような状況は望ましくありません。
より直感的なユーザーインターフェイスと、すぐに使える洞察力に満ちたレポート
GA4のインターフェイスでデータをデコードするのは大変ですか?マーケティング担当者やeコマースストアのオーナーが持ち出すGA4の最大の問題の1つです。
ウェブサイト解析の重要な役割は、意味のあるインサイトを解き明かすことです。パズルや頭の体操のように感じるべきではありません。
Matomoを使えば、セールスファネルに関する洞察を得るために、3つの異なるタイプのコンバージョン率を調べたり、カスタムレポートを作成したりする必要はありません。レポートは明確で、ナビゲートしやすく、サンプリングはありません。今まで通り。
ユーザーにはカスタムレポート、ダッシュボードを作成するオプションがあり、より詳細な解析が必要な場合は、ほぼ全てのビューをエクスポートすることが出来ます。
使い慣れたメトリクスを使い続ける
Matomoは、ほとんどのウェブマーケターやアナリストが過去10年間Googleアナリティクスを使用して慣れ親しんできた明確な指標を使用しています。それには以下が含まれます:
・ページビュー
・ユニーク訪問数
・バウンス率
・ユーザーソース
Matomoでデータサンプリングから解放
Matomoに切り替えることで、データのサンプリングや精度の問題を排除し(レポートには常に100%のデータを使用するため)、データの完全な所有権と世界で最も厳しいプライバシー規制へのコンプライアンスを提供します。
言うまでもなく、Matomoはヒートマップ、A/Bテスト、セッション記録などの行動解析機能を同じプラットフォーム内で利用でき、ユーザー体験を向上させることができます。
100万を超えるウェブサイトがMatomoアナリティクスを利用している理由は、この機能、信頼性、完全なデータ所有(サンプリングなし)の組み合わせにあります。信頼性の高いインサイトは、優れたデジタルマーケティングの基盤です。
今すぐ21日間の無料トライアル にお申し込みください。