プライバシー向上技術:データの有用性とセキュリティのバランス
2024年第3四半期、データ漏洩により4億2261万件の記録が流出し、世界中の数百万人に影響が及びました。これは、組織がユーザーのプライバシーを優先する必要性を浮き彫りにしています。
ライバシーを強化するテクノロジーは、機密情報を保護し、安全なデータ共有を可能にすることで、これを実現するのに役立ちます。
この記事では、プライバシーを強化するテクノロジーについて、その種類や利点、そして弊社のウェブサイト解析プラットフォームであるMatomoが、プライバシーに焦点を当てた機能を提供することでどのようにサポートしているかなどをご紹介します。
プライバシーを強化する技術とは?
プライバシー強化技術(PETs)とは、個人データを保護すると同時に、組織が責任を持って情報を処理できるようにするツールです。
医療、金融、マーケティングなどの業界では、業務を改善し、視聴者を効果的に絞り込むために、企業はしばしば詳細な解析を必要とします。しかし、個人データを収集し処理することは、プライバシーの問題、規制上の課題、風評リスクにつながる可能性があります。
PETは、機密情報の収集を最小限に抑え、セキュリティを強化し、ユーザーが企業のデータ使用方法をコントロールできるようにします。
以下のような世界的なプライバシー法により、PETはコンプライアンスに不可欠なものとなっています:
- 欧州連合における一般データ保護規則(GDPR)
- カリフォルニア州消費者プライバシー法(CCPA)
- カナダの個人情報保護および電子文書法(PIPEDA)
- ブラジルの個人情報保護法(Lei Geral de Protecao de Dados: LGPD)
コンプライアンス違反は、高額な罰金や風評被害などの厳しい罰則につながる可能性があります。例えば、GDPRの下では、組織は重大な違反に対して、最高2000万ユーロまたは全世界の年間売上高の4%の罰金に直面する可能性があります。
PETの種類
プライバシー保護のために利用できる技術にはどのような種類があるのでしょうか。そのいくつかを見てみましょう。
ホモモーフィック暗号化
ホモモーフィック暗号化とは、暗号テキストを復号化することなく計算を実行できる暗号技術です。復号化された結果は、プレーン・テキスト上で同じ計算を行った結果と一致します。
この技術により、処理中のデータの安全性が保たれ、ユーザーは個人情報や個人データを公開することなくデータを解析することができます。アナリストが機密性の高い顧客データを保護し、安全な取引を行う必要がある金融サービスにおいて、最も有用です。
このような利点があるにもかかわらず、同型暗号化は計算が複雑で、他の従来の手法よりも時間がかかることがあります。
Secure Multi-Party Computation (SMPC)
SMPCは、生データを明らかにすることなく、プライベート・データに対する共同計算を可能にします。
2021年、欧州データ保護委員会(EDPB)は、プライバシー要件を保護する技術としてSMPCを支持する技術ガイダンスを発表しました。これは、データ共有は必要ですが機密情報は安全に保たれなければならない医療やサイバーセキュリティにおける SMPC の重要性を浮き彫りにしています。
例えば、複数の病院が患者記録を共有することなく共同研究を行うことができます。彼らは SMPC を使用して、個々の記録を秘密にしたまま、統合されたデータを解析しています。
合成データ
合成データは、実際の情報を明らかにすることなく、実際のデータセットを模倣して人工的に生成されます。プライバシーを損なうことなくモデルをトレーニングするのに役立ちます。
ある病院が、医療記録に基づいて患者の転帰を予測するAIモデルをトレーニングしたいとします。しかし、実際の患者データを共有することはプライバシーの問題を引き起こすため、合成データでそれを変えることができます。
合成データは、実世界のデータセットの微妙なニュアンスや異常を捉えることができず、AIモデルの予測に不正確さをもたらす可能性があります。
仮名化
仮名化は、個人情報を偽名やコードに置き換えることで、その情報が誰のものかを特定することを困難にします。これにより、人々の個人情報を安全に保つことができます。仮に誰かがデータを入手したとしても、それを本物の個人に結びつけるのは容易ではありません。

仮名化は合成データとは仕組みが異なりますが、どちらも個人のプライバシー保護に役立ちます。
仮名化では、事実の情報をもとに、個人を特定できる部分を作り物のラベルに置き換えます。合成データはまったく異なるアプローチをとります。実際のデータのように見えますが、実在の人物に関する詳細を含まない、新しい人工的な情報を作成します。
差分プライバシー
差分プライバシーはデータセットにランダムなノイズを加えます。このノイズは、データの全体的な解析を可能にしながら、個々のエントリーを保護するのに役立ちます。
これは、個人情報にアクセスすることなく傾向を把握する必要がある統計調査において有用です。
例えば、毎週何時間テレビを見るかという調査を想像してください。
ディファレンシャル・プライバシーでは、各人の回答にランダムなばらつきが加わるため、ジョンやジェーンがテレビを見る時間を正確に知ることはできません。
しかし、グループ内の全員の平均視聴時間を見ることはできます。
ゼロ知識証明(ZKP)
ゼロ知識証明は、機密情報を公開することなく真実を検証するのに役立ちます。この暗号的アプローチは、証明の背後にある実際の情報を明らかにすることなく、誰かが何かを知っていることや特定の条件を満たしていることを証明することを可能にします。
実際の例としてZCashを見てみましょう。Bitcoinが金融取引の詳細をすべて公開するのに対し、ZCashはZero-Knowledge Succinct Non-Interactive Arguments of Knowledge (zk-SNARKs)と呼ばれる特殊な証明によってプライバシーを提供しています。これらの数学的証明は、誰が送金し、誰がそれを受け取り、いくらやり取りされたかを公表することなく、取引がすべてのルールに従っていることを確認します。
しかし、この技術にはトレードオフがあります。
これらの証明の作成とチェックには膨大なコンピューティング・パワーが要求されるため、取引が遅くなり、コストが上昇します。このようなシステムを導入するには、高度な暗号技術に関する深い専門知識が必要となるため、多くの組織では、その利点にもかかわらず、採用が見送られています。
信頼された実行環境(TEE)
TEEは、コンピュータ・プロセッサの内部に特別な保護されたゾーンを作り、そこで機密コードが安全に実行されます。これらのセキュアな領域は、見るべきでない人からデータを遠ざけながら、貴重なデータを処理します。
TEEは、モバイル決済、デジタル著作権管理(DRM)、クラウド・コンピューティングなどの高セキュリティ・アプリケーションで広く使用されています。
企業がクラウドで TEE をどのように使用しているかを考えてみましょう:企業は、Microsoft AzureやAWS Nitro Enclaves上の保護された領域で、暗号化されたデータセットを実行することができます。このセットアップにより、クラウドプロバイダでさえ、プライベートデータにアクセスしたり、企業がどのようにそのデータを使用しているかを確認したりすることはできません。
TEEには限界があります。分離された設計のため、大規模な計算タスクや分散した計算タスクに対応できず、複数のシステムにまたがる複雑な計算には適していません。
異なるTEEの実装には標準化が欠けていることが多く、互換性の問題や特定のベンダーに依存することがあります。ベンダーが製品を停止したり、誰かがセキュリティ上の欠陥を発見したりした場合、新しいソリューションに切り替えるには、多くの場合、費用と手間がかかります。
難読化(データマスキング)
データマスキングは、無許可のアクセスを防ぐために、機密データを置き換えたり隠したりすることを含みます。
これは、機密データを架空のものですが現実的な値に置き換えます。例えば、顧客のクレジットカード番号は「1234-XXXX-XXXX-5678」とマスキングされるかもしれません。
元のデータは永続的に変更されるか隠され、マスキングされたデータは元の値を再現することができません。
フェデレーテッド・ラーニング
フェデレーテッド・ラーニングとは、データを一元化することなく、複数のデバイスにまたがってアルゴリズムを学習させる機械学習のアプローチです。この方法により、組織はユーザーのプライバシーを維持しながら、分散したデータソースからの洞察を活用することができます。
例えば、NVIDIAのClaraプラットフォームは、医療画像(例えば、MRIスキャンにおける腫瘍の検出)用のAIモデルを訓練するために、連合学習を使用しています。
世界中の病院がそれぞれのローカルデータセットからモデルの更新を提供し、患者のスキャンを共有することなくグローバルモデルを構築します。このアプローチは、脳卒中のタイプ分類やがん診断の精度向上に利用できるかもしれません。
さて、ここまで様々な種類のPETについて見てきましたが、PETの開発と使用の指針となる原理を理解することが不可欠であります。
PETの重要な原則(+Matomoでそれを実現する方法)
PETはデータの有用性とプライバシー保護のバランスを取ることを目的としたいくつかの核心的原則に基づいています。これらの原則には次のものが含まれます:
データ最小化
データ最小化とは、必要なデータのみを収集し保持することに焦点を当てたPETの基本原則です。
オープンソースのウェブ解析プラットフォームであるMatomoは、プライバシーとデータ保護を優先しながら、ウェブサイトトラフィックとユーザー行動に関する洞察力を収集するのに役立ちます。
データ最小化の重要性を認識し、Matomoはこの原則を積極的にサポートするいくつかの機能を提供しています:
- クッキーを使わないトラッキング: クッキーへの依存を排除し、不必要なデータ収集を削減します。
- IP匿名化: IPアドレスを自動的に匿名化し、個々のユーザーの特定を防ぎます。
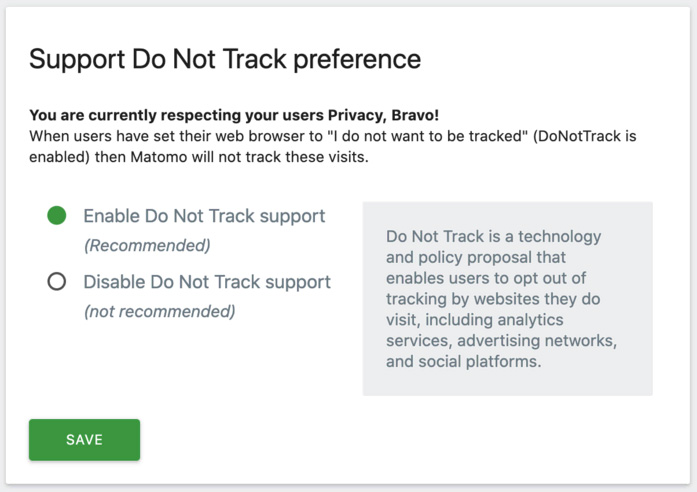
–オプトアウトの仕組み: これには、訪問者がトラッキングをオプトアウトできるようにするiframe機能が含まれます。
セキュリティと機密性
セキュリティと機密性は、不適切なアクセスから機密データを保護します。
Matomo は次のような方法でこれを実現しています:
- オンプレミスホスティング:オンプレミスホスティング: 解析データをオンサイトでホスティングし、データを完全にコントロールすることができます。
- データセキュリティ:アクセスコントロール、監査ログ、二要素認証、SSL暗号化により、保存された情報を保護します。
- オープンソースコード:コミュニティによるレビューを可能にし、セキュリティと透明性を向上。
目的制限
目的の限定とは、組織が意図された目的のみにデータを使用し、第三者に共有したり販売したりしないことを意味しています。
Matomoは、デフォルトでファーストパーティのクッキーを使用することで、この原則を守っています。Matomoは100%のデータ所有権を提供します。つまり、Matomoのウェブ解析から得られるデータはすべてその組織のものであり、外部への販売は一切行いません。
プライバシー規制への準拠
Matomoは、GDPR、CCPA、HIPAA、LGPD、PECRなどのグローバルなプライバシー法に準拠しています。そのコンプライアンス機能は以下の通りです:
- 設定可能なデータ保護:Matomoは、個人を特定できる情報(PII)の追跡を避けるように設定できます。
- データ対象者要求ツール:法的枠組みに従って、データの削除やアクセスなどの要求を処理するためのメカニズムを提供します。
- GDPRマネージャー:Matomoは、訪問者ログの削除や監査証跡など、説明責任をサポートする機能を提供することで、企業のコンプライアンス管理を支援するGDPRマネージャーを提供しています。
そのため、プライバシーと GDPR コンプライアンスを尊重しつつ、サイトの強みと摩擦点について詳細なフィードバックを得られるウェブ解析ソリューションを探していました。Matomoは、そのすべてを満たしてくれました。
データコラボレーション:PETsの重要な使用例
PETsが非常に有用である特定の分野の1つは、データコラボレーションです。データ・コラボレーションは、組織にとって研究とイノベーションのために重要です。しかし、データのプライバシーは危機に瀕しています。
そこで、データ・クリーン・ルームやウォール・ガーデンといったツールが重要な役割を果たします。これらは1種類以上のPETを使用し(PETそのものではない)、安全なデータ解析を可能にします。
ウォールドガーデンはデータアクセスを制限しますが、プラットフォーム内での解析は許可します。データクリーンルームは、生データを共有することなくデータ解析のための安全な空間を提供し、多くの場合、暗号化のようなPETを使用します。
PETによるプライバシー問題への取り組み
データ漏洩やプライバシーに関する懸念の中で、組織はデータから有用な洞察を得つつ、機密情報を保護する方法を見つけなければなりません。PETの使用は、データを保護し、顧客の信頼を構築するのに役立つため、これらの問題を解決するための重要なステップとなります。
Matomoのようなツールは、データを安全に保ちながら、組織がプライバシー法を遵守するのに役立ちます。また、個人が自分の個人情報をよりコントロールできるようになるため、100万ものウェブサイトがMatomoを利用しています。
Matomoへの切り替えは簡単です。